

今天巧豚豚想和大家聊一聊亚马逊竞品分析。
数据分析领域有一句名言:Garbage in, Garbage out,垃圾数据进,垃圾数据出。
当我们在分析的第一步,选择对标竞品时,如果圈定的参照物不够精准,那么后续得出的所有关键词和市场容量数据,都是被污染的。怎么做更好呢?
在评估一个市场或一款产品时,需要从两个不同层级的视角来进行分析。
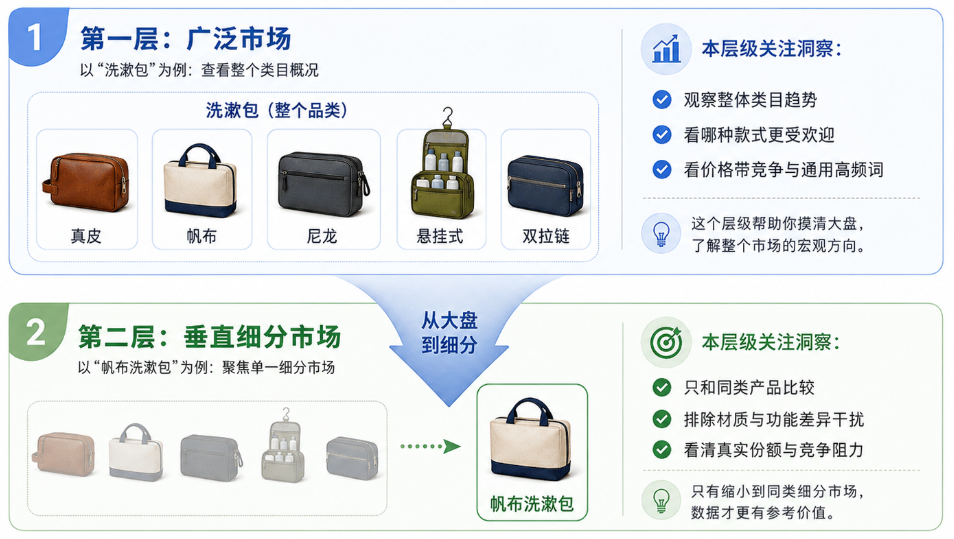
第一层,广泛市场
假设你打算切入 “洗漱包” 这个市场,广泛市场的概念就是包含真皮、帆布、尼龙、悬挂式、双拉链等所有材质和款式的整体大盘。在这个视角下,你需要观察的是整个类目的宏观趋势:目前市面上哪种款式最受消费者欢迎?哪个价格带的竞争最激烈?在这个大类目下,消费者高频搜索的通用词汇有哪些?这些宏观数据能帮你摸清大盘的底牌。
然而不同材质和功能的受众群体,搜索习惯和购买诉求是不同的。这就要求我们进入第二个视角。
第二层,垂直细分市场
如果你最终决定售卖的是一款 “帆布洗漱包”,那么你在广泛市场中看到的 “真皮洗漱包” 或 “尼龙洗漱包” 的数据意义其实并不大。你需要做的是不断缩小范围,只将自己的产品与同类的 “帆布洗漱包” 进行比较。只有在排除了材质、功能差异带来的数据干扰后,才能清晰地看到自己在这个特定小圈子里的真实市场份额,以及你需要克服的具体竞争阻力。
明确了垂直细分市场之后,接下来的关键环节是挑选具体的对标竞品。
在这个步骤很容易贪多,觉得分析的竞品越多,数据越全面。但适当的做减法有时候效果会更好。
- 重质不重量
通常情况下,挑选 8 到 10 个高度匹配且表现优秀的竞品就已经足够勾勒出清晰的市场轮廓了。不要为了凑够几十个竞品的数量,去硬塞入那些销量惨淡或者根本没有核心自然排名的产品。一个连自然搜索流量都获取不到的竞品,是无法为我们提供有价值的关键词参考的。
- 警惕虚假繁荣竞品
另一方面,我们需要警惕那些看似销量高,但实际上不可参考的虚假繁荣竞品。
如果你发现某个排名前列的卖家,其流量几乎全部来源于他们自身的品牌词搜索,应该将这类竞品从分析名单中剔除。因为我们很难通过常规的通用关键词去抢夺这部分品牌忠诚度极高的流量。
- 多变体竞品
遇到带有多个颜色或尺寸变体的竞品时,我们同样需要做减法。不要将整个父 ASIN 的数据笼统地拿来分析,要锁定那个贡献了绝大部分销量、且与自身产品定位最接近的变体。这样提取出来的数据,更贴合未来的真实运营场景。
在分析过程中,需要避开两个常见的思维误区。
第一个,唯大词论
有些卖家可能喜欢用搜索量最大的单一核心词来概括整个品类的需求。实际上,消费者的搜索路径是发散的。一个购买洗漱包的消费者,可能会搜索男士大容量防水洗漱包,也可能会搜索适合出差的旅行收纳袋。一两个大词难以反映市场需求全貌,还会让你错失高转化、低竞争的长尾词。
第二个,数据混合
试想一下,如果竞品池里既有男士洗漱包,又混杂了几款女士化妆包,那么当我们导出关键词时,词库里就会有类似女士化妆、口红收纳等毫无用处的词汇。这种被污染的数据一旦用于撰写Listing 或投放广告,不仅会浪费广告预算,还会扰乱亚马逊系统对产品的标签定位,导致系统把产品展示给错误的人群。
落地实操:我们该如何将这些理念落地到日常运营?
第一步:数据清洗
当我们通过精心筛选的 8-10 个核心竞品导出了一批流量关键词后,第一项工作是进行数据大扫除,剔除掉竞品的品牌名、与产品特性不符的属性词,缺乏逻辑的错误词。
第二步:词库分级
清理完毕后,对这份干净的词库进行维度分级。巧豚豚建议可以依据两个指标来评估一个词的价值:
一是相关性,即这 8-10 个竞品中,有多少家同时在这个词下获得了良好的自然排名;二是搜索量。
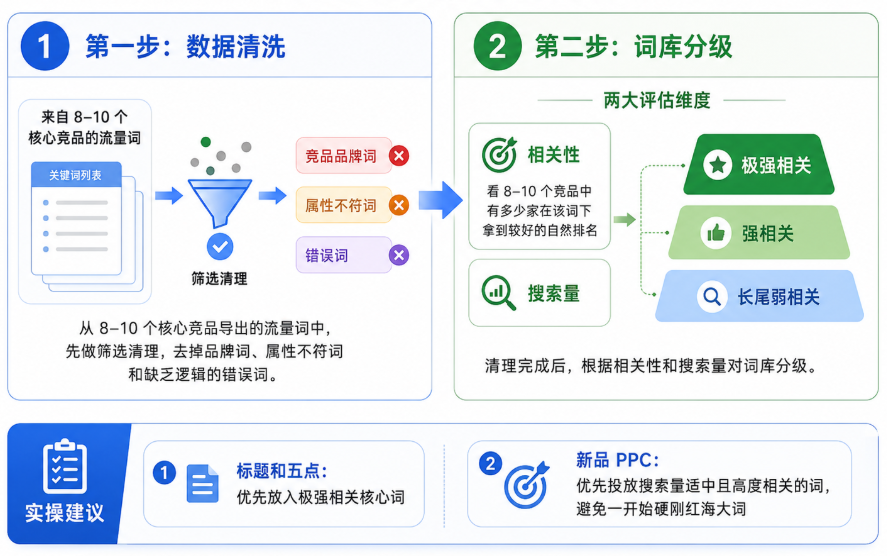
基于这两个维度,可以把词库划分为极强相关、强相关以及长尾弱相关等不同梯队。
在写 Listing 的时候把那些极强相关的核心词语巧妙地埋入标题和五点描述的黄金位置中。
在产品上架的新品期,不要盲目去和老卖家硬刚红海大词,优先提取那些搜索量适中且高度相关的词汇去开启 PPC 广告,通过精准点击和转化来为新品积攒初期的权重与势能。
回顾一下主题,竞品分析在精不在多,选对有用的竞品分析出来的关键词才更有用。大家在日常做竞品分析时,还遇到过什么令人头疼的问题吗?欢迎在评论区留言,我们一起讨论!







